

How To Find Interval Estimate Of A Population Mean
| Confidence Interval on the Hateful David K. Lane Help support this free site by ownership your books from Amazon following ane of these links: Prerequisites Areas Under Normal Distributions, Sampling Distribution of the Mean, Introduction to Estimation, Introduction to Confidence IntervalsLearning Objectives
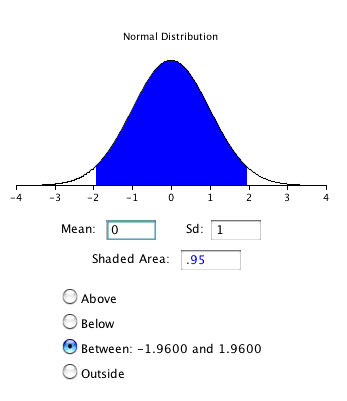
View Multimedia Version When you lot compute a confidence interval on the mean, you compute the hateful of a sample in lodge to estimate the mean of the population. Clearly, if you already knew the population hateful, in that location would be no need for a confidence interval. Still, to explain how confidence intervals are constructed, we are going to piece of work backwards and begin by bold characteristics of the population. Then we will show how sample information can be used to construct a confidence interval. Assume that the weights of 10-year-onetime children are normally distributed with a mean of 90 and a standard departure of 36. What is the sampling distribution of the mean for a sample size of ix? Call back from the section on the sampling distribution of the hateful that the mean of the sampling distribution is μ and the standard fault of the hateful is For the present example, the sampling distribution of the mean has a mean of 90 and a standard deviation of 36/3 = 12. Note that the standard deviation of a sampling distribution is its standard error. Figure 1 shows this distribution. The shaded expanse represents the heart 95% of the distribution and stretches from 66.48 to 113.52. These limits were computed by calculation and subtracting 1.96 standard deviations to/from the mean of ninety as follows: xc - (i.96)(12) = 66.48 The value of 1.96 is based on the fact that 95% of the area of a normal distribution is within 1.96 standard deviations of the mean; 12 is the standard mistake of the mean. Figure one. The sampling distribution of the hateful for N=9. The center 95% of the distribution is shaded. Figure 1 shows that 95% of the means are no more than 23.52 units (i.96 standard deviations) from the mean of ninety. Now consider the probability that a sample mean computed in a random sample is within 23.52 units of the population mean of xc. Since 95% of the distribution is within 23.52 of 90, the probability that the mean from any given sample volition be within 23.52 of xc is 0.95. This means that if we repeatedly compute the mean (M) from a sample, and create an interval ranging from K - 23.52 to One thousand + 23.52, this interval will contain the population mean 95% of the time. In general, you compute the 95% conviction interval for the mean with the post-obit formula: Lower limit = M - Z.95σM Upper limit = M + Z.95σ1000 where Z.95 is the number of standard deviations extending from the mean of a normal distribution required to contain 0.95 of the area and σChiliad is the standard fault of the mean. If you await closely at this formula for a confidence interval, you will notice that you lot need to know the standard departure (σ) in guild to estimate the hateful. This may sound unrealistic, and it is. However, calculating a conviction interval when σ is known is easier than when σ has to be estimated, and serves a pedagogical purpose. Afterwards in this section we volition show how to compute a confidence interval for the hateful when σ has to be estimated. Suppose the following v numbers were sampled from a normal distribution with a standard difference of 2.5: 2, 3, 5, 6, and 9. To compute the 95% confidence interval, start by computing the mean and standard error: Effigy 2. 95% of the area is between -1.96 and 1.96. Normal Distribution Calculator The confidence interval can then be computed as follows: Lower limit = 5 - (1.96)(ane.118)= 2.81 Yous should use the t distribution rather than the normal distribution when the variance is not known and has to be estimated from sample data. When the sample size is big, say 100 or above, the t distribution is very like to the standard normal distribution. Nonetheless, with smaller sample sizes, the t distribution is leptokurtic, which means it has relatively more scores in its tails than does the normal distribution. As a result, y'all have to extend further from the mean to contain a given proportion of the area. Recall that with a normal distribution, 95% of the distribution is within 1.96 standard deviations of the mean. Using the t distribution, if you have a sample size of just five, 95% of the area is within 2.78 standard deviations of the mean. Therefore, the standard error of the mean would exist multiplied by 2.78 rather than 1.96. The values of t to be used in a conviction interval tin can be looked upwardly in a table of the t distribution. A small version of such a table is shown in Table 1. The beginning column, df, stands for degrees of freedom, and for confidence intervals on the mean, df is equal to N - 1, where N is the sample size. Table 1. Abbreviated t table.
You lot tin can also employ the "inverse t distribution" computer to observe the t values to use in confidence intervals. You will learn more most the t distribution in the next department. Assume that the following five numbers are sampled from a normal distribution: two, three, five, 6, and 9 and that the standard deviation is not known. The first steps are to compute the sample hateful and variance: M = 5 The adjacent stride is to approximate the standard error of the mean. If we knew the population variance, we could use the post-obit formula: The next step is to find the value of t. As you can see from Table one, the value for the 95% interval for df = Due north - 1 = 4 is two.776. The confidence interval is then computed just equally it is when σM. The only differences are that sThou and t rather than σM and Z are used. Lower limit = 5 - (two.776)(1.225) = ane.60 More by and large, the formula for the 95% confidence interval on the mean is: Lower limit = Thou - (tCL)(sM) where M is the sample hateful, tCL is the t for the confidence level desired (0.95 in the in a higher place example), and sM is the estimated standard error of the mean. Nosotros will finish with an analysis of the Stroop Data. Specifically, we will compute a conviction interval on the mean difference score. Recall that 47 subjects named the color of ink that words were written in. The names conflicted so that, for instance, they would name the ink colour of the discussion "blue" written in red ink. The correct response is to say "ruddy" and ignore the fact that the give-and-take is "blue." In a second status, subjects named the ink color of colored rectangles. Tabular array 2. Response times in seconds for 10 subjects.
Tabular array 2 shows the time departure between the interference and color-naming conditions for 10 of the 47 subjects. The mean time difference for all 47 subjects is 16.362 seconds and the standard deviation is 7.470 seconds. The standard error of the mean is one.090. A t tabular array shows the critical value of t for 47 - 1 = 46 degrees of freedom is 2.013 (for a 95% confidence interval). Therefore the conviction interval is computed as follows: Lower limit = 16.362 - (two.013)(ane.090) = 14.17 Therefore, the interference effect (departure) for the whole population is likely to be between fourteen.168 and 18.555 seconds. Make sure to put the data file in the default directory. Data file data=read.csv(file="stroop.csv") Please reply the questions: |
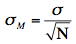

 = i.225
= i.225
Source: https://onlinestatbook.com/2/estimation/mean.html
Posted by: jacksonwasce1943.blogspot.com
0 Response to "How To Find Interval Estimate Of A Population Mean"
Post a Comment